
沉浸式视觉体验:机遇性视频生成模型评估框架的深度解析
沉浸式视觉体验:机遇性视频生成模型评估框架的深度解析
亲爱的读者朋友们,今天我们将一起探索视频生成模型在具身智能任务中的新评估框架以及相关的技术细节,让我们为人工智能的未来感到兴奋吧!
一、具身智能任务的崛起与评估的重要性
具身智能任务近几年正迅速崛起,成为AI领域的研究热点。我们所指的具身智能,是指智能体(如机器人、自动驾驶系统等)通过环境感知与交互来完成特定任务的能力。在机器人应用中,如何让机器能够有效刺探环境、识别路径并最终顺利完成任务,都是实际运用中的重大挑战。

随着技术的进步,视频生成模型的发展为具身智能提供了新的解决方案。想象一下,一台机器人在一个复杂环境中快速判断、灵活应对,它的背后支撑着的是准确而迅捷的视频生成模型。然而,现有评估标准仍偏重于视觉效果,未能有效衡量模型的实际应用能力。
这使得我们引发思考:仅靠一幅静态图片或一段优美视频,真的能够全面评估模型在真实世界中的表现能力吗?为了改变这种局面,研究团队们开始寻找更为全面的评价方法,通过结合视觉质量与物理一致性的双重视角来实现这一目标。
二、WorldSimBench的崭新评估框架
随着对评估方法的深入研究,WorldSimBench评估框架应运而生。这一框架不仅量化了视频生成模型的真实应用能力,同时也重新定义了评估智能体工作的标准。这不仅是技术上的突破,更是AI与真实世界交互的重要一步。
在该框架中,研究者们设计了两大评估维度:显性感知评估和隐性操作评估。显性感知评估主要基于人类的视觉反馈,强调视频生成的视觉质量和物理一致性。而隐性操作评估关注的是具体任务执行的有效性,例如生成的视频是否能够有效指导智能体完成物理操作。
这一创新使得我们对于生成模型的认识更加全面,真实且多维的评估能够帮助我们理解一个模型在实际场景下的潜力。例如,想象一段视频在复杂场景下的实时反馈与决策能力,一种全新的视角下形成的评估方法无疑将极大推动相关领域的发展。
三、视频生成模型的分级分析
研究团队将视频生成模型划分为四个阶段,以便清晰地描述它们在具身智能能力上的成熟度。这个分级不仅为研究提供了更为细致的标准,也帮助业界和学术界有效理解不同模型的特性。
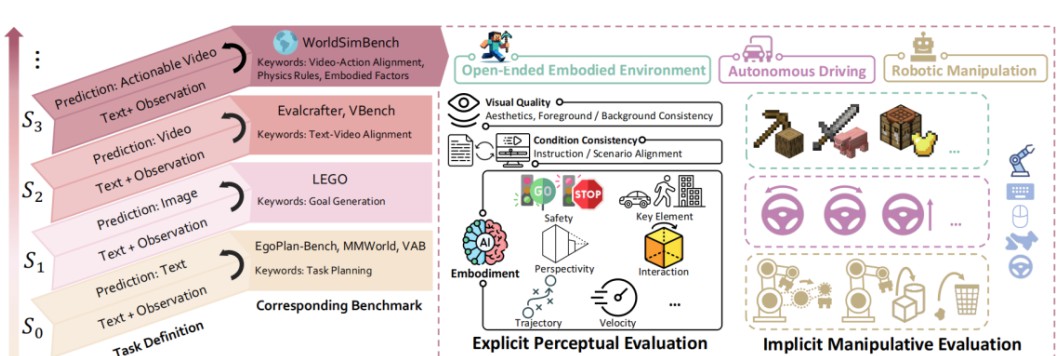
1. S0阶段:在此阶段,模型仅关注于生成视觉内容,完全不涉及具身智能的表现。类似于单纯的图片生成算法,如GANs(生成对抗网络)。虽然结果可能在视觉上吸引人,但在实际应用中毫无意义。
2. S1阶段:这里的模型已经能够生成与特定任务场景相关的视频,譬如在环境中的静态图像生成。尽管与场景关联,但缺乏实时反应和动态互动能力。
3. S2阶段:此时模型开始具备一定的物理一致性,能够生成简易动作的视频。这个阶段如同儿童学步,具备基本的移动能力,尝试去执行一些简单的动态任务,但仍乏力应对更复杂的环境。
4. S3阶段(世界模拟器):这是模型在这一领域的终极表现,能够生成完全符合物理规则的视频,成功带动智能体完成特定的具身任务。想象在真实交通中驾驶的自动驾驶汽车,毫无疑问,需要凶险的城市环境与动态因素来考验它的反应能力。
这一分级系统不仅便于研究者理解各模型的长短期发展路径,也为未来的算法优化和技术进步制定了清晰的目标和方向。
四、实验验证与评估结果
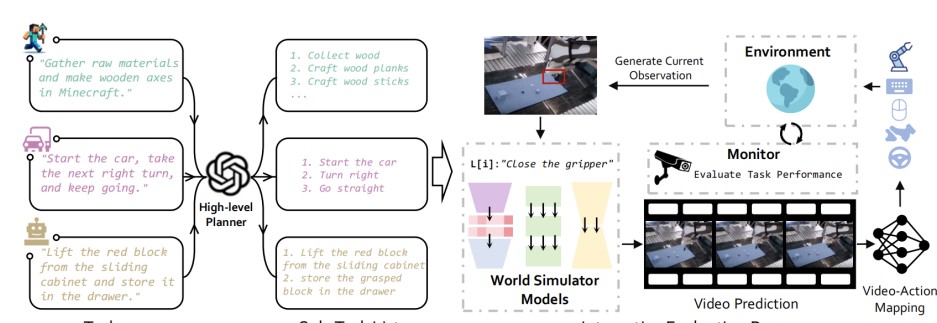
在评估通过WorldSimBench框架的模型时,研究团队对多个具身智能环境进行了反复测试,以求在不同应用场景中获得更准确的数据和结果。
- MineRL环境:这个环境基于我的世界(Minecraft),它为评估视频生成模型在开放式环境中的表现提供了可能。智能体的任务是要在虚拟环境中完成诸如采集物品、导航等任务。通过采用WorldSimBench框架,研究者们能够判断生成视频能否有效引导智能体执行操作,确保了模型的实用性和有效性。
- CARLA自动驾驶平台:这是一个专门用于测试自动驾驶算法的仿真平台,利用复杂的城市交通情况进行评估。研究人员通过模拟各种交通场景,比如行人过马路、车辆行驶等,来观察生成的视频如何影响智能体的决策能力。评估指标包括路线完成度、碰撞率和违规行为等,体现了模型在真实情况中的威胁识别与规避能力。
- CALVIN机器人操作环境:该环境用于评估视频生成模型在进行精确操作时的表现,比如抓取物体、搬运等。在这个高复杂度的环境中,生成的视频必须准确反映物体的位置与运动轨迹,否则会造成错误或事故的发生。评估的成功率、轨迹生成质量等数据为模型优化提供了重要依据。
实验中得出的结论非常明确,基于WorldSimBench框架的评估,不仅能更好地捕捉到模型在视觉生成中的细微差异,同时也能够反映人类期望与生成视频的一致性,这一切都是传统模型所无法比拟的。
五、评估框架的挑战与展望
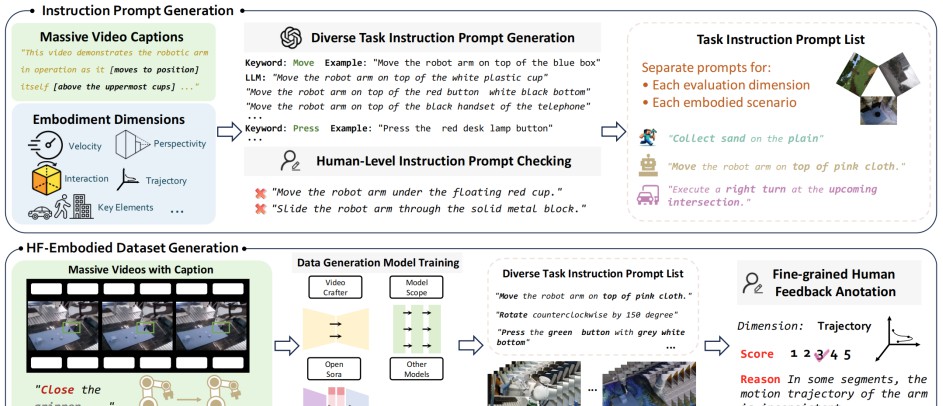
尽管WorldSimBench在视频生成模型的评估方面已取得了显著的进展,但其发展依然面临不少挑战。在进行评估时,HF-Embodied数据集的构建与应用便是一大难题。该数据集依赖大规模人工标注数据,实施成本高昂、数据更新速度慢,让研究进展受到制约。
现有的评估主要集中在虚拟环境中,如何将这些成功的评估方法应用到真实世界同样是一个亟待解决的问题。例如,现实中的交通情况充满不可预测性,这要求生成的模型必须具备巨大的灵活性与应对能力。因此,未来在真实世界环境中的评估与优化将是大势所趋。
要让视频生成模型成为真正的“世界模拟器”,需要付出更大的努力和资源,在数据集构建、算法优化等多个领域进行深耕细作。这不仅是这一研究团队的任务,更是整个AI社区需要共同面对的挑战。

欢迎大家在下方留言讨论,分享您的看法!