
特征衍生大揭秘:建模效果飙升秘诀!
探索特征衍生:解锁建模效果的秘密武器
在数据驱动的世界中,特征工程无疑是机器学习项目中不可或缺的一环。而在特征工程中,特征衍生(Feature Derivation)则像是一把锋利的剑,能够帮助我们挖掘出数据中隐藏的宝藏,进而提升模型的性能。今天,就让我们一起走进特征衍生的世界,探索其背后的奥秘和技巧。
特征衍生,简而言之,就是通过现有数据创造新的特征。它像是一个神奇的魔术师,通过对原始数据进行重新排列、组合、转换,变出一个个全新的特征。这些新特征往往能够揭示数据的深层规律,为模型提供更丰富的信息,从而增强模型的预测能力。
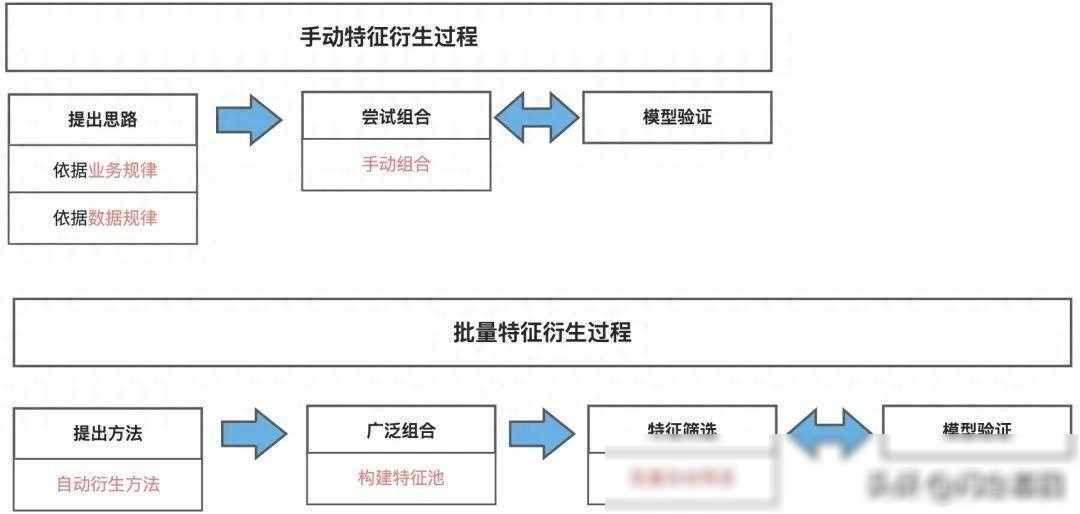
特征衍生主要有两种类型:手工特征衍生和批量特征衍生。手工特征衍生依赖于数据背景和业务背景的分析,通过人工合成字段来创建新特征。这种方法虽然耗时耗力,但创建的特征往往具有较强的业务背景与可解释性,同时也能够更精准、有效地提升模型效果。相比之下,批量特征衍生则更加高效,它通过一些工程化手段批量创建特征,然后从海量特征池中挑选有用的特征进行建模。虽然这种方法可能产生大量无效特征,但它能够快速拓展特征空间,为模型提供更多的选择。
特征衍生的本质其实是对既有数据信息的重新排布。无论是手工特征衍生还是批量特征衍生,都是在不断地挖掘、发现数据中潜在的关联和规律。这些关联和规律往往能够为我们揭示数据的真实面貌,从而帮助我们更好地理解数据、预测未来。
在手工特征衍生中,我们通常会从思路出发,先分析数据集当前的业务背景或数据分布规律,然后再根据这些分析结果进行特征衍生。比如,在电商领域中,我们可以根据用户的购买历史和浏览行为,衍生出用户的购物偏好、兴趣点等特征。这些特征不仅能够更准确地描述用户的行为模式,还能够为推荐系统提供更精准的推荐策略。
而在批量特征衍生中,我们则更加注重方法的创新和应用。我们会从数据的特点和模型的需求出发,寻找合适的特征衍生方法。比如,我们可以利用多项式特征衍生来创建变量的高次方数据,从而捕捉数据中的非线性关系;我们还可以利用分组统计特征衍生来根据某个特征的不同取值进行分组统计,从而揭示数据中的层次结构和分布规律。
当我们掌握了特征衍生的本质和类型之后,接下来就需要了解具体的特征衍生方法了。这些方法就像是我们手中的武器库,只有掌握了它们的使用方法,我们才能在特征衍生的战场上游刃有余。
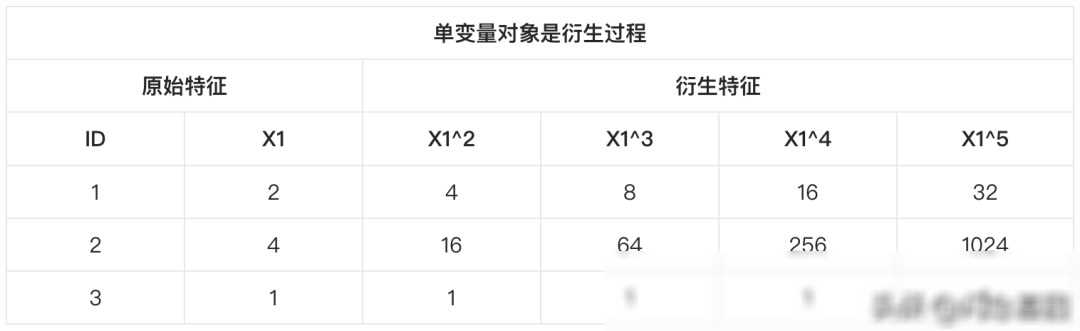
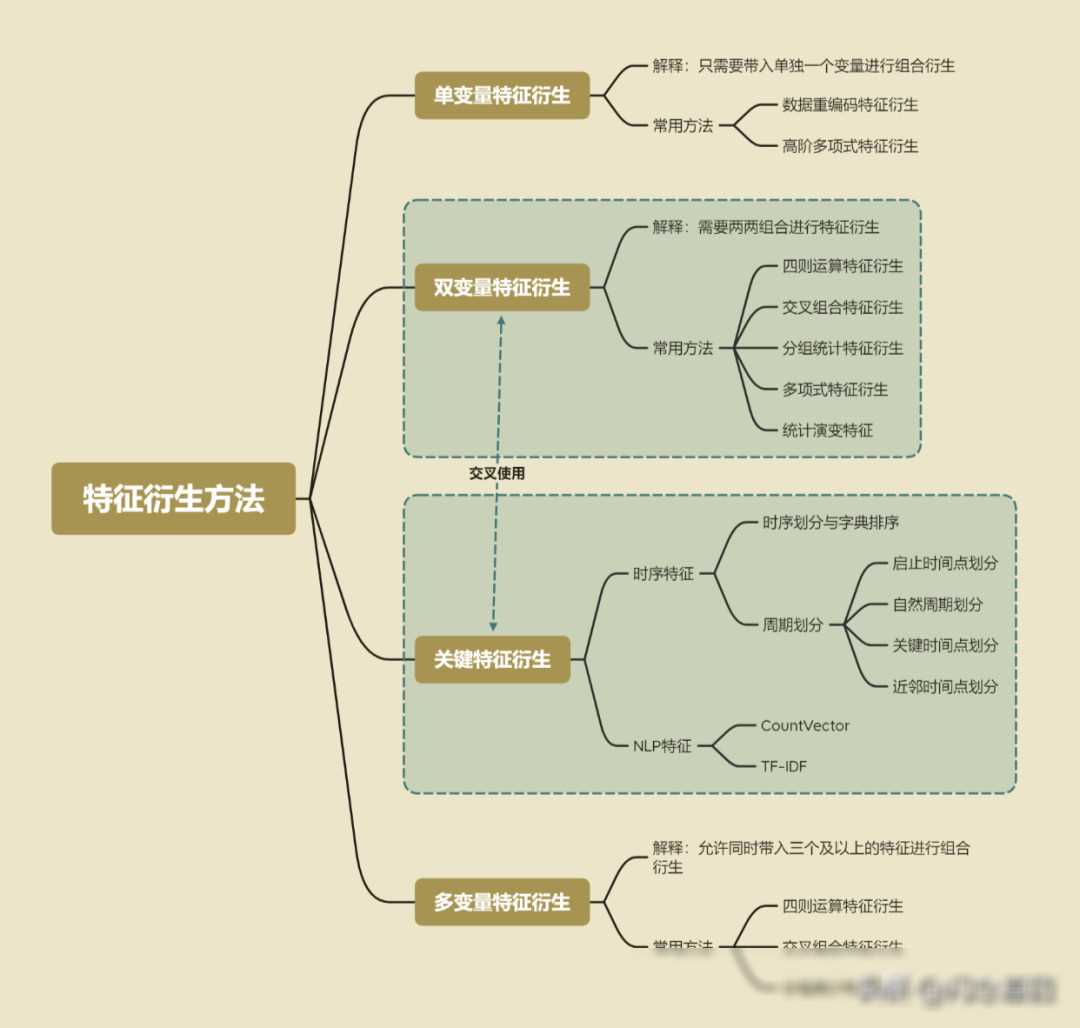
单变量特征衍生:这是最简单的一种特征衍生方法,它主要关注单个变量的变换和衍生。比如,我们可以对连续变量进行分箱(Binning)处理,将其转换为离散变量;我们还可以对离散变量进行编码(Encoding),将其转换为数值型数据。这些变换不仅能够简化模型的处理过程,还能够揭示数据的深层规律。
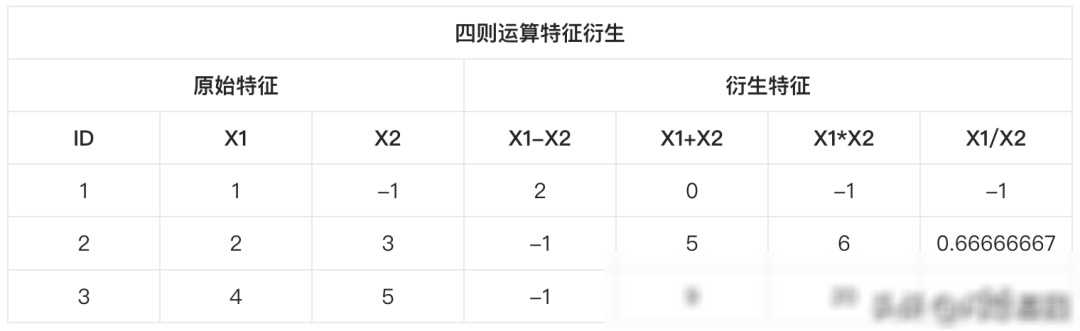
双变量特征衍生:当涉及到两个变量时,我们可以尝试将它们进行交叉组合或运算来创建新特征。比如,我们可以将两个连续变量相乘或相除来创建新的特征;我们还可以将两个分类变量进行交叉组合来创建新的分类特征。这些新特征往往能够揭示两个变量之间的关联和规律,为模型提供更丰富的信息。
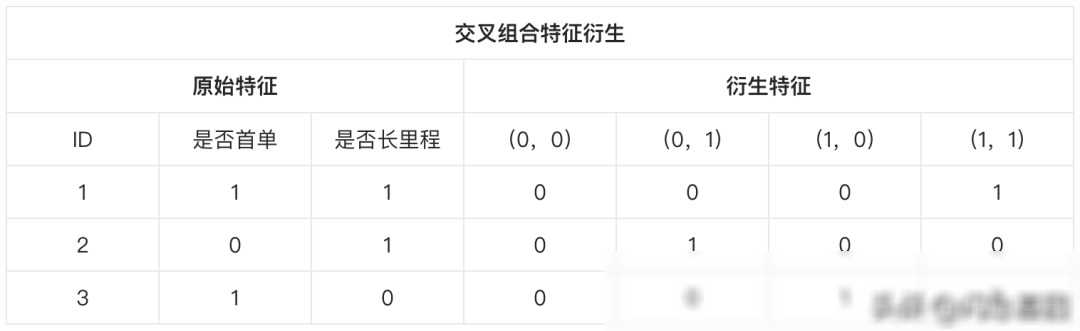
多变量特征衍生:当涉及到多个变量时,我们可以尝试将它们进行组合或运算来创建新特征。但是需要注意的是,随着变量数量的增加,特征的数量也会呈指数级增长,这可能会导致计算资源的浪费和模型性能的下降。因此,在进行多变量特征衍生时,我们需要谨慎选择变量和衍生方法,避免产生过多的无效特征。
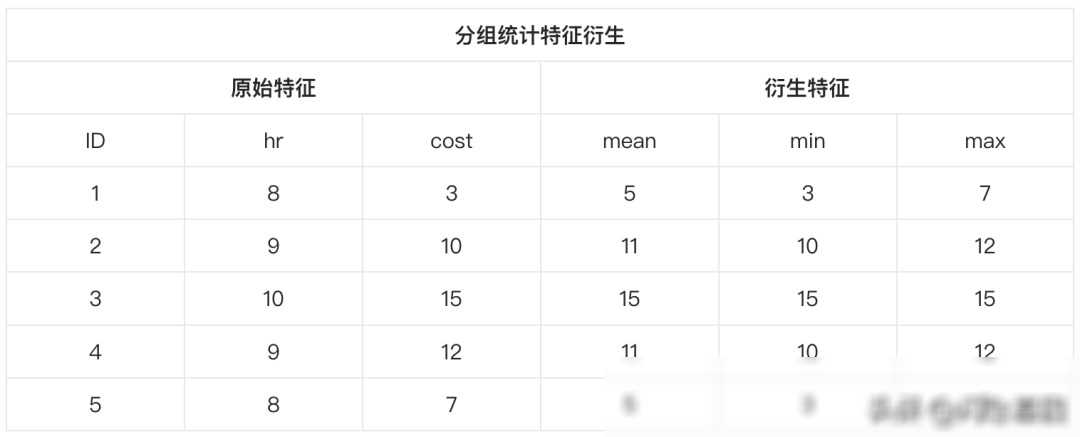
在进行特征衍生时,我们并不是无节制地朝着无限特征的方向前进。相反地,我们需要遵循一些准则来指导我们的工作。这些准则就像是我们手中的指南针,帮助我们找到正确的方向。
有效性:首先,我们需要确保衍生出的特征是有效的。这意味着这些特征应该能够为模型提供有用的信息,而不是简单的数据噪声。因此,在进行特征衍生时,我们需要根据数据的特点和模型的需求来选择合适的衍生方法。
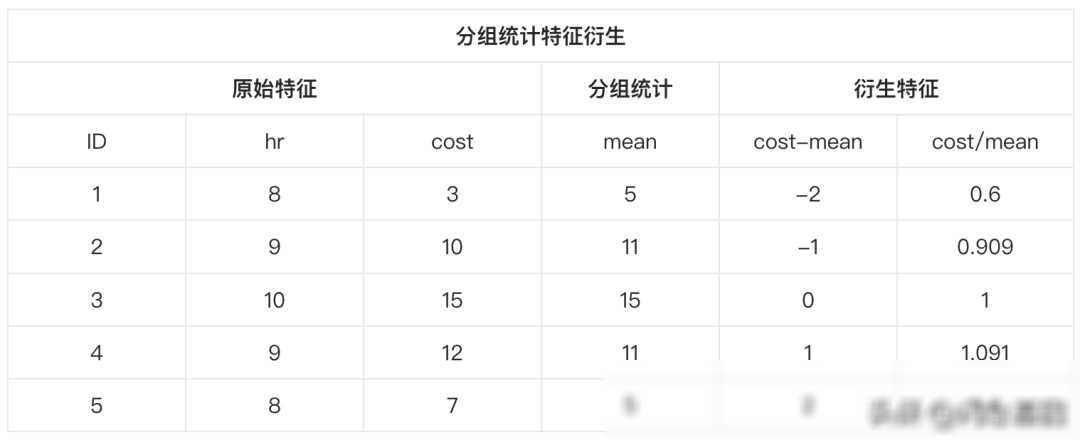
可解释性:其次,我们需要确保衍生出的特征具有可解释性。这意味着这些特征应该能够被人类理解和解释,而不是仅仅作为黑盒子中的一部分。因此,在进行特征衍生时,我们需要尽可能选择具有明确业务含义的衍生方法,避免产生过于复杂的特征。
效率:最后,我们需要确保特征衍生的过程是高效的。这意味着我们需要尽可能地减少无效特征的生成和筛选过程,提高特征衍生的效率。为此,我们可以采用一些自动化工具和技术来辅助我们进行特征衍生和筛选工作。
特征衍生是机器学习项目中不可或缺的一环。通过特征衍生,我们可以挖掘出数据中隐藏的