打造专属大型语言模型,开启AI新时代!
如何开始定制你自己的大型语言模型
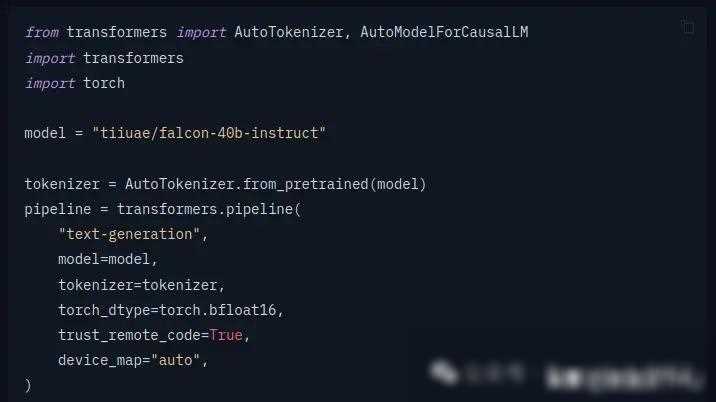
随着人工智能技术的飞速发展,大型语言模型(LLMs)如GPT-3、BERT等已经成为我们生活中不可或缺的一部分。它们不仅在自然语言处理领域大放异彩,还在各种应用场景中发挥着重要作用。对于许多开发者来说,定制一个符合自己需求的大型语言模型似乎是一件遥不可及的事情。今天,我们就来聊聊如何开始定制你自己的大型语言模型,让技术的魅力触手可及。
一、大型语言模型的魅力与挑战

大型语言模型之所以吸引人,是因为它们能够处理海量的文本数据,并从中学习到丰富的语言知识。这些模型通过深度学习技术,能够生成流畅、自然的文本,甚至在某些任务上超越了人类的表现。定制一个大型语言模型并非易事,它需要大量的计算资源、优质的训练数据和深厚的技术实力。
二、硬件资源准备:高性能与低性能的权衡
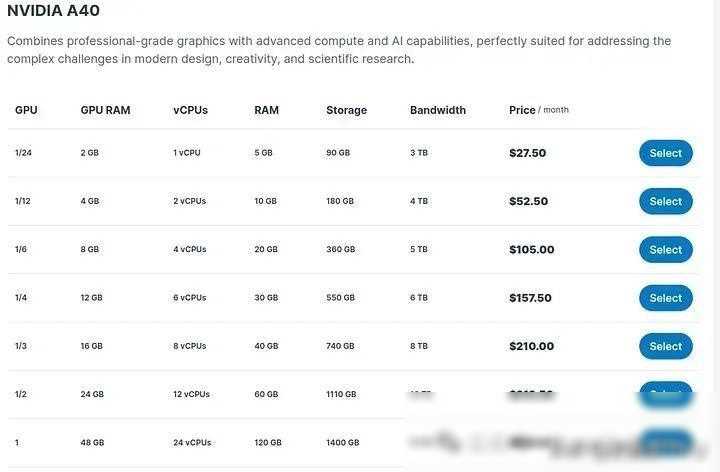
在定制大型语言模型之前,我们首先需要准备足够的硬件资源。这里有两种选择:高性能和低性能。高性能模型通常拥有庞大的参数规模,能够处理更复杂的任务,但也需要更高的计算成本和更长的训练时间。对于个人开发者或小型企业来说,低性能模型可能是一个更实际的选择。它们虽然参数规模较小,但在一些特定场景下也能取得不错的效果。

在选择硬件时,我们需要考虑自己的需求和预算。如果你打算训练一个高性能模型,那么你可能需要租用高性能的GPU云服务器或购买昂贵的GPU硬件。而如果你只是想学习或进行简单的实验,那么一个价格适中的GPU就足够了。
三、数据集准备:优质数据的力量
除了硬件资源外,数据集也是定制大型语言模型的关键因素。一个优质的数据集应该具有足够的规模和多样性,以覆盖尽可能多的语言现象和任务场景。数据集的质量也非常重要,它应该经过清洗和标注,以减少噪声和错误。
在准备数据集时,我们可以从各种来源获取文本数据,如网络爬虫、公开数据集、社交媒体等。然后,我们需要对数据进行预处理,包括分词、去停用词、去除特殊符号等步骤。我们可以将数据划分为训练集、验证集和测试集,以便在训练过程中进行模型评估和调优。
四、模型训练:从基础到进阶
有了硬件和数据集之后,我们就可以开始训练大型语言模型了。在训练过程中,我们需要选择合适的深度学习框架和模型架构,并设置合适的超参数。我们还需要关注训练过程中的各种指标,如损失函数、准确率等,以便及时调整模型参数和优化算法。
在训练初期,我们可以先使用较小的模型参数和简单的任务进行尝试,以熟悉整个训练流程。随着对技术的深入理解,我们可以逐渐增加模型参数和任务的复杂度,以获得更好的性能表现。
在训练过程中,我们还需要关注模型的泛化能力和鲁棒性。这意味着我们的模型不仅能够处理训练数据中的情况,还能对未见过的数据进行合理的预测和推断。为了提高模型的泛化能力,我们可以采用一些正则化技术、数据增强方法等手段。
五、模型评估与调优:精益求精
当模型训练完成后,我们需要对其进行评估和调优。评估模型性能的方法有很多种,如准确率、召回率、F1值等。我们还可以使用一些专门的评估工具或数据集来测试模型的性能表现。
在评估过程中,我们可能会发现模型在某些方面表现不佳。这时,我们可以通过调整模型参数、更换模型架构、增加训练数据等方法来优化模型性能。我们还可以关注一些最新的研究成果和技术趋势,以便将最新的技术应用到我们的模型中。
六、模型应用与部署:让技术落地
当我们的模型达到满意的性能表现后,就可以将其应用到实际场景中去了。大型语言模型的应用场景非常广泛,如文本生成、文本分类、机器翻译、问答系统等。我们可以根据自己的需求选择合适的场景进行应用。
在应用过程中,我们还需要关注模型的稳定性和可维护性。这意味着我们的模型应该能够稳定地运行并处理各种异常情况。我们还需要定期更新和维护模型,以保证其性能和效果不受影响。
七、结语:技术的力量与责任

通过本文的介绍,我们了解了如何开始定制大型语言模型的基本流程和方法。虽然定制一个大型语言模型需要投入大量的时间和精力,但只要我们掌握了正确的技术和方法,就能够打造出符合自己需求的高性能模型。
我们也需要意识到技术的力量与责任。在享受技术带来的便利和乐趣的我们也需要关注技术的潜在风险和挑战。例如,大型语言模型可能会产生一些不准确的预测或偏见,我们需要通过合理的设计和使用来避免这些问题。我们也需要关注技术的伦理和社会影响,确保技术的健康发展和广泛应用。
我想说的是,定制大型语言模型不仅是一项技术挑战,更是一次探索未知领域的冒险之旅。让我们携手共进,在技术的道路上不断前行!