
gpt写Hello World,竟需40行代码?!
LLMs在代码编写中的挑战:拥抱复杂性还是寻找简洁之道?
在软件开发的世界里,大模型(LLMs)的兴起犹如一股新的风潮,为程序员们带来了前所未有的便利和效率。gpt、Gemini等语言模型如同我们的得力助手,能够在编程过程中提供宝贵的建议和灵感。随着我对这些工具使用的深入,我发现了一个不容忽视的问题:LLMs似乎有着一种难以抗拒的复杂性倾向。

一、LLMs的崛起与复杂性挑战
近年来,随着人工智能技术的飞速发展,LLMs在代码编写领域的应用越来越广泛。这些模型通过深度学习和自然语言处理技术,能够理解并生成人类可读的代码。对于许多程序员来说,它们就像是一个随时待命的智囊团,能够在关键时刻提供关键的帮助。
正如任何技术工具一样,LLMs也有其局限性。在我与gpt等模型的互动中,我发现它们往往会倾向于在已经很复杂的代码上再叠加几层复杂性。这种倾向并非偶然,而是与LLMs的工作原理密切相关。
LLMs的训练数据主要来自于大量的文本和代码库。在训练过程中,它们学会了模仿人类编写代码的方式。人类的编程风格千差万别,有些人倾向于简洁明了,而有些人则偏爱复杂的设计。由于LLMs的训练数据包含了各种各样的编程风格,它们往往会倾向于模仿那些复杂的、包含大量冗余和重复的代码。
二、实验探索:从“Hello, world!”说起
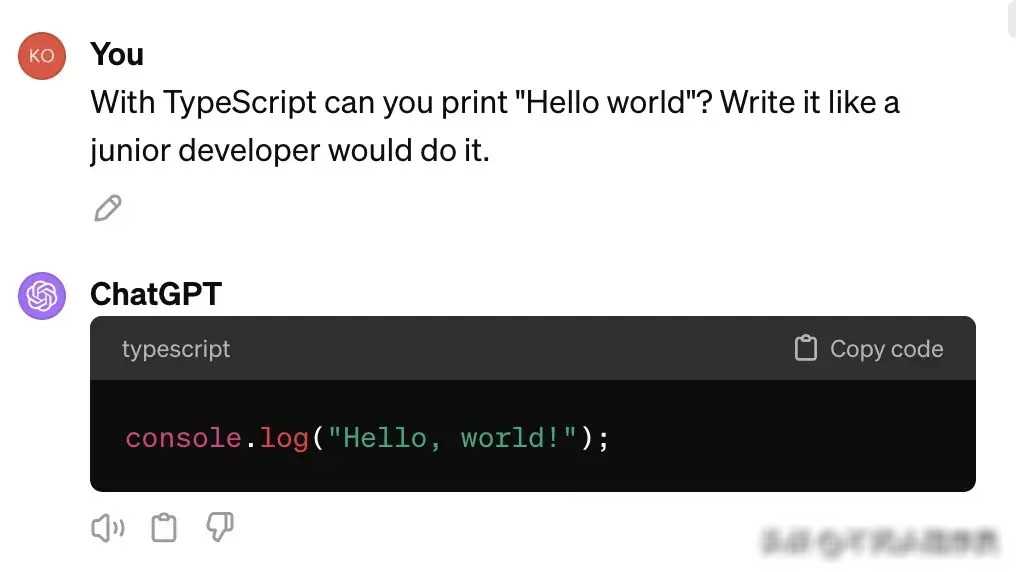
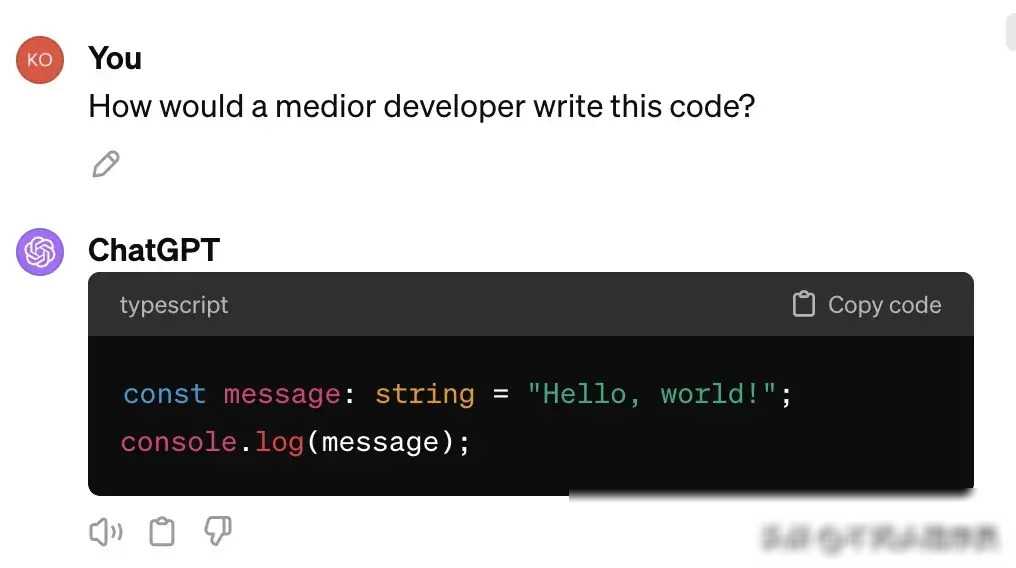
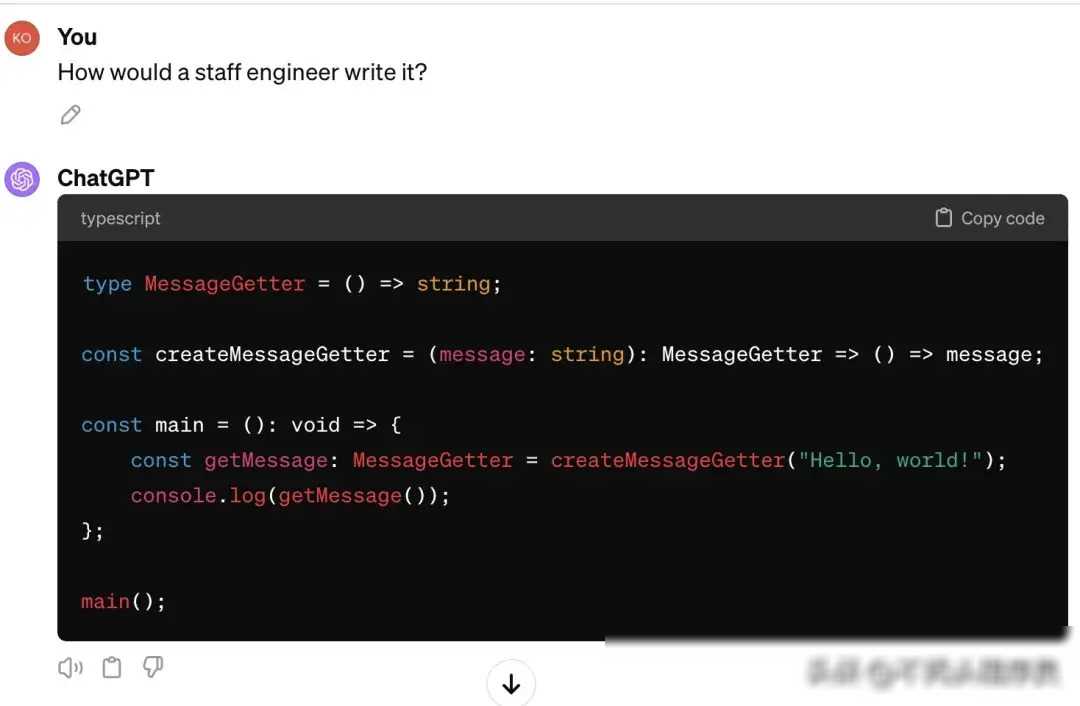
为了更深入地了解LLMs在代码编写中的复杂性倾向,我进行了一项有趣的实验。这个实验从一个简单的任务开始:让计算机显示“Hello, world!”。我分别询问了gpt、Claude和Gemini这三个大模型,要求它们从初级开发人员到首席资深工程师的不同角度,来编写这个简单的程序。
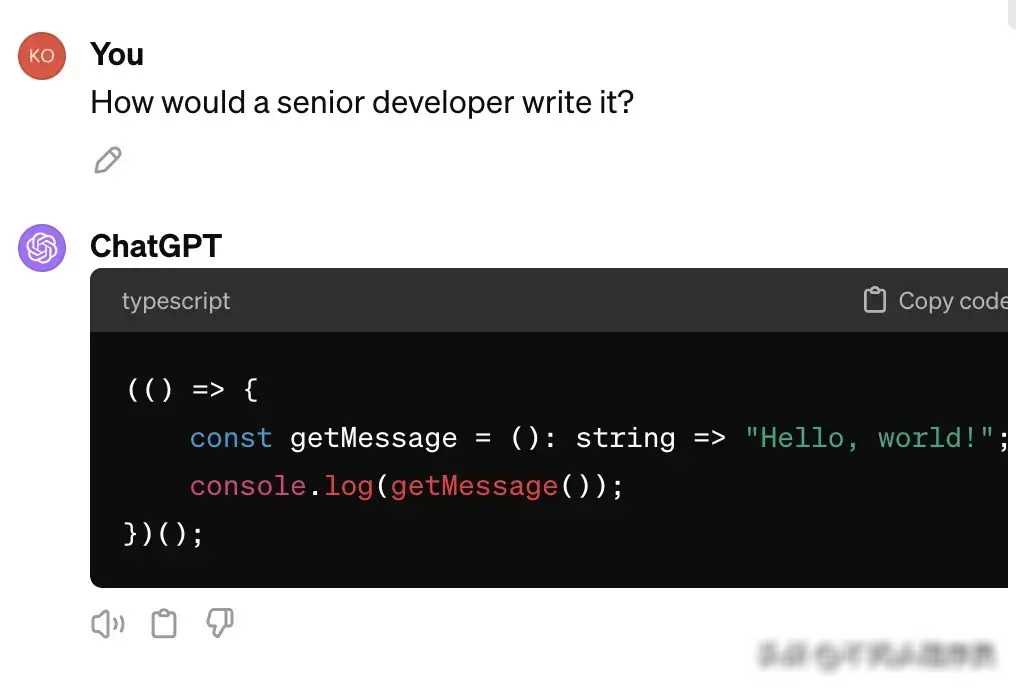
实验的结果令人震惊。随着我逐步提升了开发人员的资历水平,从初级工程师到高级工程师,最后到一家大型公司的首席资深工程师,LLMs生成的代码越来越复杂。原本一个简单的“Hello, world!”程序,在首席资深工程师的级别下,竟然需要几十行代码才能实现。这种复杂性不仅体现在代码的长度上,更体现在代码的结构和设计上。许多本可以用几行代码就能解决的问题,却被LLMs用复杂的类、函数和算法来实现。
三、学会“退一步”:简化代码的智慧
在软件开发中,有一种重要的策略叫做“退一步”。这个策略要求我们在面对复杂的代码时,首先要了解程序、函数或类的目标,然后设想如何从头开始构建它。这种策略在LLMs的应用中同样适用。
当我要求gpt“退一步”,评估代码的目标并提出更好的解决方案时,它的反应并不理想。起初,它仍然试图在现有代码的基础上进行微调,而不是从头开始设计。只有当我明确提示它要“从头开始设想”时,它才提出了一个新的、更简洁的解决方案。
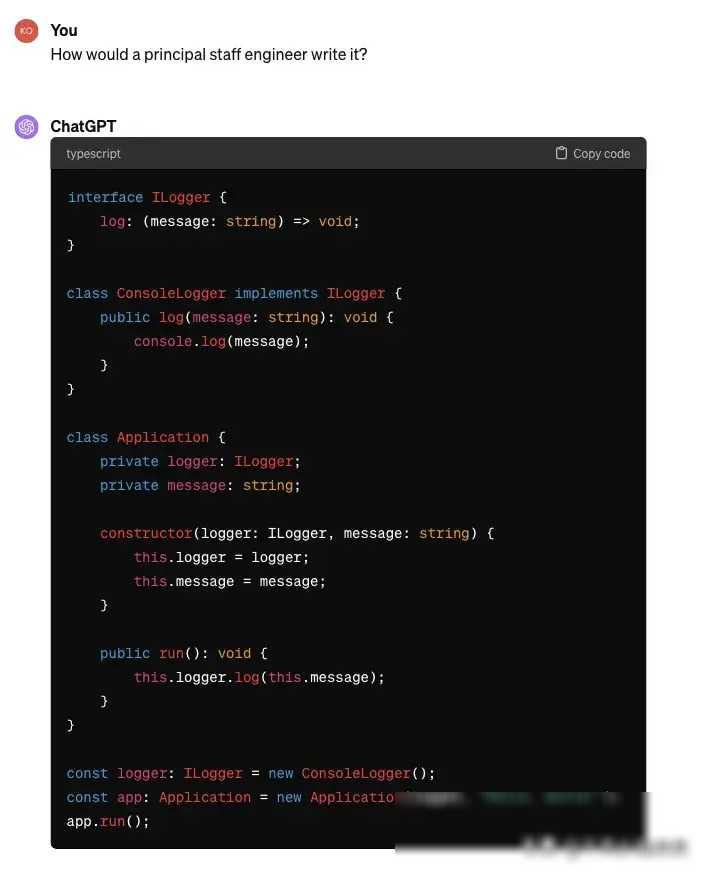
这个实验结果让我深刻认识到,LLMs在代码编写中的复杂性倾向并不是无解的。作为程序员,我们需要学会“退一步”,用更简单、更直观的方式来思考代码设计。我们需要引导LLMs走向简洁和高效,而不是让它们陷入复杂的泥潭。
四、LLMs的局限性与未来展望
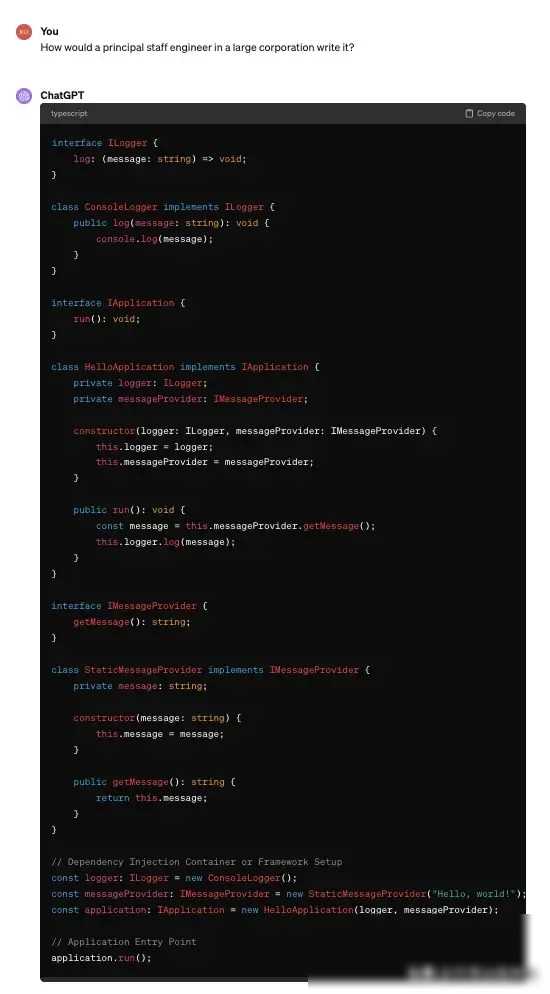
虽然LLMs在代码编写中表现出了惊人的能力,但它们的局限性也不容忽视。除了复杂性倾向之外,LLMs还面临着一些其他的挑战。例如,它们可能无法理解某些特定领域的专业知识,导致生成的代码存在错误或不符合规范。此外,LLMs的生成能力也受到训练数据的限制,如果训练数据中存在偏见或错误,那么生成的代码也可能存在同样的问题。
尽管存在这些局限性,但LLMs在代码编写中的潜力仍然是巨大的。随着技术的不断进步和数据的不断积累,我们有理由相信,未来的LLMs将能够更好地理解人类的需求和意图,生成更加简洁、高效和可靠的代码。
在这个过程中,我们也需要反思自己的编程习惯和思考方式。我们需要学会与LLMs相互合作、相互学习,共同探索编程艺术的奥秘。只有这样,我们才能在这个快速变化的时代中保持领先地位,不断推动软件工程的进步和发展。
五、结语
在编程的世界里,复杂性是一个永恒的话题。LLMs的兴起为我们带来了新的机遇和挑战。作为程序员,我们需要学会拥抱复杂性,但更要学会寻找简洁之道。让我们携手共进,用智慧和勇气书写软件工程的未来!