
OCR+大模型:文件识别分类神器!
基于OCR和大模型的文件识别及分类系统
一、引言
在数字化时代,我们每天都需要处理大量的文档。无论是企业的合同、报告,还是个人的账单、收据,这些纸质或电子文档都需要被有效地管理和分类。但传统的手动分类方法效率低下,且容易出错,已经无法满足现代高效工作的需求。幸运的是,随着技术的发展,我们可以借助OCR(光学字符识别)和大模型技术来构建一个智能的文件识别及分类系统。这样的系统能够自动识别和分类文档,大大提高工作效率和准确性。
二、系统概述
2.1 系统目标
我们的目标是构建一个能够自动识别和分类文档的智能系统。这个系统能够遍历指定文件夹下的文档和图片,提取其中的关键词,然后根据这些关键词将文件自动分类并转移到指定目录。这样,用户就无需手动整理大量的文档,节省了大量时间和精力。
2.2 系统功能简述

这个智能系统主要有以下几个功能:它能够遍历用户指定的文件夹,自动识别和读取其中的文档和图片;通过OCR技术,系统能够提取文档和图片中的文本信息;接着,利用大模型技术对这些文本进行深度分析和理解,提取出关键词;根据这些关键词,系统能够自动将文件分类并转移到相应的目录中。
三、技术栈介绍
3.1 OCR技术
OCR技术是光学字符识别的缩写,它能够从扫描文档、图像或照片中提取文本信息。在我们的系统中,OCR技术扮演着关键角色,它负责将文档和图片中的文本信息提取出来,供后续的分类和分析使用。Python中有很多优秀的OCR库,如Tesseract和Pytesseract,它们能够识别多种语言的文本,并处理不同质量和格式的图像。
3.2 大模型技术
大模型技术,如BERT、GPT等,是现代自然语言处理领域的重要成果。这些模型经过大规模的预训练,能够理解语言的深层语义。在我们的系统中,大模型技术被用于对OCR提取的文本进行深度分析和理解,从而提取出关键词和主题。通过微调这些模型,我们可以使其更好地适应特定的分类任务。
3.3 向量存储与语义分析
为了提高分类的准确性和效率,我们将文本转换为向量表示。这些向量可以存储在专门的向量数据库中,如Milvus或M3E。当新文档到来时,系统可以通过计算其向量与数据库中已有向量的相似度来确定其类别。此外,语义分析也在这个过程中发挥着重要作用。通过分析文档中的关键词和概念,系统可以更准确地理解文档的意图和上下文。
四、系统开发步骤
4.1 安装运行环境
在开始开发之前,我们需要安装必要的运行环境和依赖库。这包括Python环境、OCR库(如Tesseract和Pytesseract)、大模型库(如Transformers)以及向量数据库(如Milvus或M3E)。安装过程可以根据官方文档或相关教程进行。
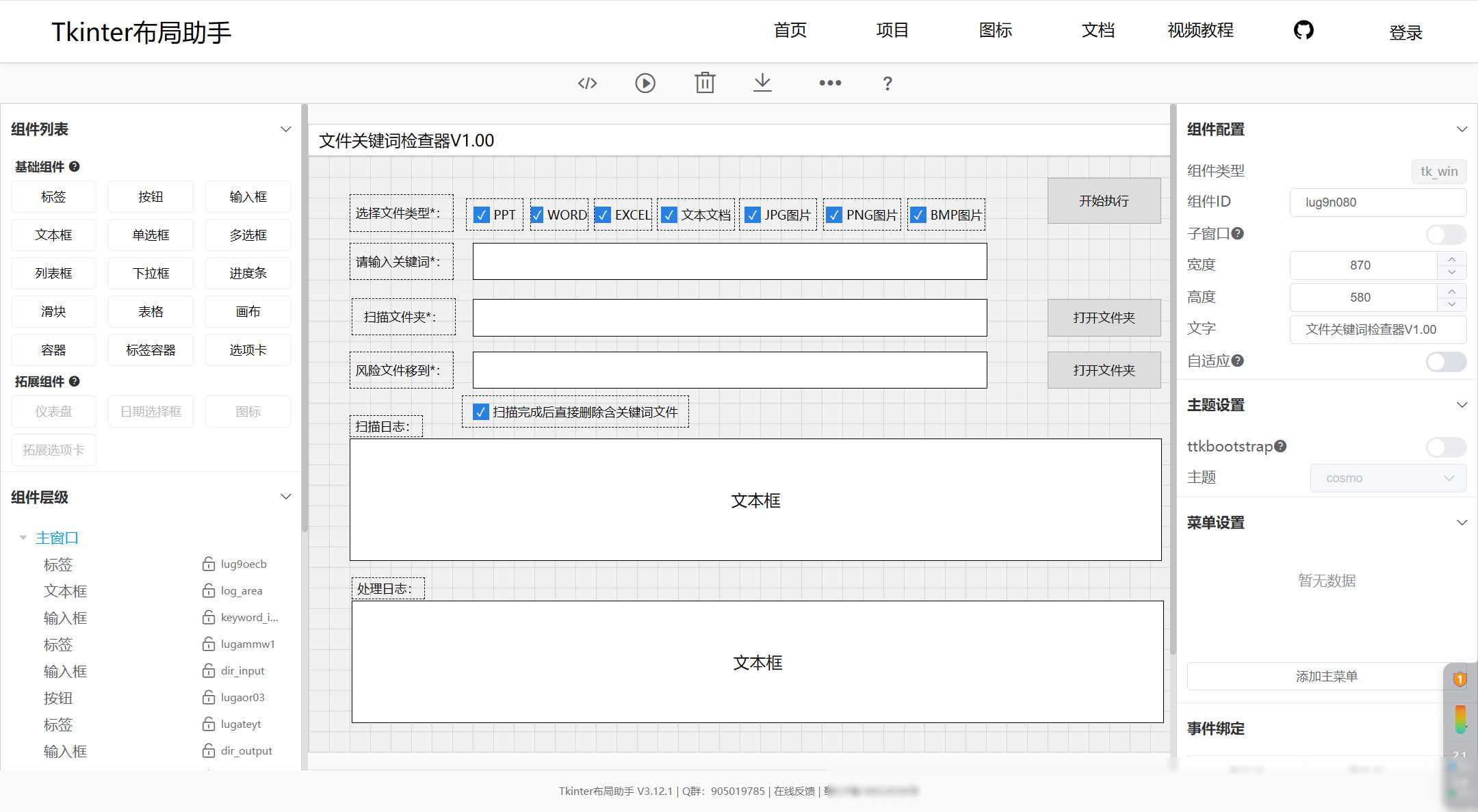
4.2 制作UI界面
为了方便用户使用,我们可以制作一个简单的UI界面。这个界面可以是一个图形化的操作窗口,允许用户选择要扫描的文件夹、设置分类目录以及查看分类结果等。我们可以使用第三方程序或框架来快速搭建这个界面,如PyQt、Tkinter等。
4.3 实现动作函数与核心功能

接下来是实现系统的核心功能。这包括遍历文件夹、读取文件和图片内容、提取关键词、分类文件以及转移文件等。我们可以使用Python的os和shutil库来遍历和操作文件,使用OCR库来提取文本信息,使用大模型技术来分析文本并提取关键词,最后根据关键词将文件分类并转移到指定目录。
4.4 读取并存储文件及图片信息
在这一步中,我们将使用OCR技术读取文件和图片中的文本信息,并使用M3E等向量数据库将这些信息存储为向量表示。我们还会记录文件的其他相关信息,如文件路径、名称、大小、创建时间等。这些信息将有助于后续的文件查询和管理。
4.5 根据语义查询与转移文件
当用户需要查询或检索文件时,系统可以根据用户输入的关键词或语义进行向量相似度计算,从而快速找到相关的文件。系统还可以根据用户的指令自动将文件转移到指定的目录或进行其他操作。
4.6 系统打包与发布
在完成所有功能的开发和测试后,我们可以将系统打包为一个可执行文件或安装包,方便用户下载和安装。这样,其他用户就可以轻松地使用我们的智能文件识别及分类系统了。

通过结合OCR和大模型技术,我们成功地构建了一个智能的文件识别及分类系统。这个系统能够自动识别和分类大量的文档和图片,大大提高了工作效率和准确性。通过简单的UI界面和强大的功能,我们也为用户提供了一个便捷、高效的文件管理工具。