
DBRX登顶开源大模型!编程数学超GPT-3.5!
DBRX:开源大模型的新王者
当我们谈论人工智能领域的大模型时,很多人可能会首先想到GPT系列,它们在语言理解、生成和推理方面展现出了强大的能力。最近一个名为DBRX的开源大模型的出现,让这个领域再次掀起了波澜。
一、DBRX的崭新登场
DBRX,这个由Databricks公司发布的开源大模型,一经推出就引起了业界的广泛关注。为什么它如此引人注目呢?它拥有惊人的1320亿参数,这个数字在开源大模型中可谓是佼佼者。而且,无论是基础版本还是微调版本,DBRX都毫不吝啬地向公众开放,这无疑为开发者和研究者提供了宝贵的资源。
二、性能超越,与领先模型并驾齐驱
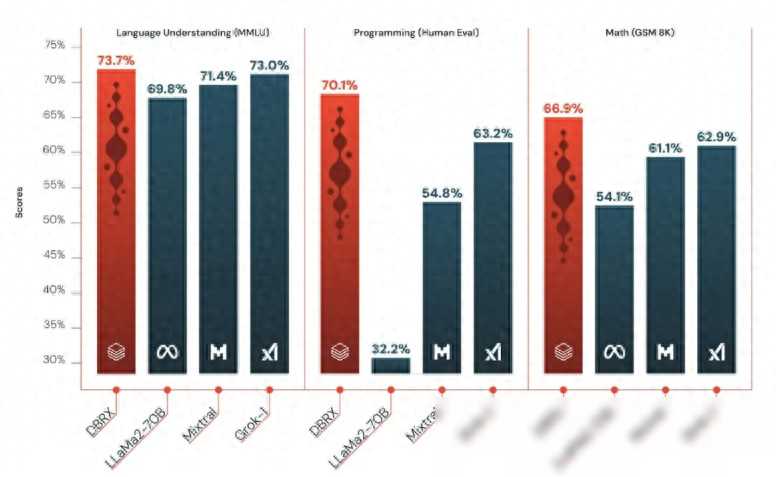
性能是评判一个大模型好坏的关键指标之一。DBRX在语言理解、编程、数学等多个领域都展现出了超越GPT-3.5的实力。这不仅仅是在某些特定任务上的超越,而是在综合性能上有着全面的提升。更值得一提的是,它与闭源的领先模型Gemini1.0Pro和Mistral Medium相比也毫不逊色。
想象一下,当你需要一个能够理解和生成自然语言、编写代码、解决数学问题的智能助手时,DBRX无疑是一个极佳的选择。它不仅能够提供高质量的输出,还能在处理复杂任务时展现出惊人的推理能力。
三、技术细节:混合专家模型与高效训练
DBRX之所以如此强大,离不开其背后的技术支持。它采用了混合专家模型架构,这种架构允许模型在处理不同任务时调用最合适的“专家”来完成。这种灵活性使得DBRX能够更高效地处理各种复杂问题。
此外,DBRX还使用了一系列先进的技术来提升模型的质量和效率。比如旋转位置编码、门控线性单元和分组查询注意力等,这些技术都是为了让模型在处理自然语言时更加准确和高效。而GPT-4分词器的加入,则进一步提升了模型的分词准确性,使得其在理解和生成自然语言时更加得心应手。
四、速度与效率的完美结合
除了性能强大之外,DBRX在推理速度上也取得了显著的突破。它平均只需激活360亿参数就能处理一个token,这使得其推理速度几乎比LLaMA2-70B快了两倍。在Mosaic AI Model Serving平台上,DBRX甚至可以达到每秒处理150个token的速度。
这种高效率意味着在实际应用中,DBRX能够更快地给出响应,无论是在线聊天机器人、智能助手还是其他需要实时反馈的场景中,DBRX都能提供出色的表现。
五、DBRX的影响力与应用前景
DBRX的出现无疑为开源AI模型领域树立了新的标杆。它不仅在性能上超越了众多领先模型,还在效率和推理速度上取得了显著的突破。这使得DBRX在开源社区和商业应用中都具有极高的价值。
对于开发者来说,DBRX提供了一个强大的工具来加速他们的项目开发进程。无论是在自然语言处理、编程还是数学计算方面,DBRX都能提供有力的支持。而对于商业应用来说,DBRX的高效推理速度和强大性能也使其成为了一个极具吸引力的选择。
六、总结与展望
DBRX的问世为开源大模型领域注入了新的活力。它以其出色的性能和效率赢得了开发者和研究者的青睐。随着技术的不断进步和应用场景的不断拓展,我们有理由相信DBRX将在未来发挥更大的作用。无论是在自然语言处理、编程助手还是其他智能应用中,DBRX都将成为不可或缺的一部分。让我们期待DBRX在未来能为我们带来更多的惊喜和可能性吧!