
30秒内实现声音克隆!探索17K明星级开源工具的奇妙能力
探索AI声音克隆技术——OpenVoice
一、引言

随着人工智能技术的迅猛发展,许多曾经只存在于科幻小说中的概念,今天都变成了现实。想象一下,是否曾有那么一刻,你希望能够以某个知名人士的声音来表达自己的想法?或者,想要在游戏中为角色配音,使用自己最喜欢的明星的声音?在这样的背景下,声音克隆技术应运而生,OpenVoice就是其中的一颗璀璨明珠。
OpenVoice究竟是什么?它如何在短短30秒内,利用一小段音频样本,准确克隆出你所期望的声音?这不仅是科技的奇迹,更让我们对声音的定义和使用有了全新的认识。接下来,我们将深入探讨OpenVoice的工作原理、优势,以及它在当今社会的应用前景。
二、OpenVoice概述
1. 工具介绍
OpenVoice是一个由AI创业公司openshell所开发的开源声音克隆工具。它的最大亮点在于,只需提供一段约30秒的音频样本,无论是来自于你本人,还是名人的演讲,OpenVoice都能准确**该声音的独特特征。它不仅可以模拟具体的声调,还能做到语言和口音的多样化。
你是否想过,为什么声音克隆技术如此重要?在当今的数字时代,声音不仅仅是传播信息的工具,更是个性和情感的载体。OpenVoice的出现,正是为了让这一点变得更加简单和普及。
2. 技术原理
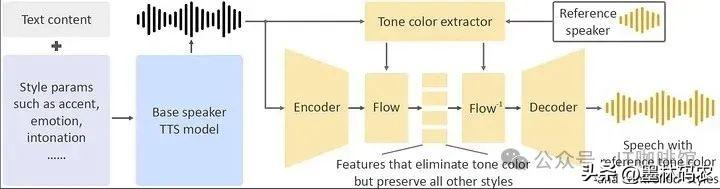
OpenVoice的核心在于深度学习技术,尤其是神经网络。通过对音频样本的分析,系统能够识别声波的频率、音调、节奏等参数,甚至可以捕捉到微小的情感变化。想象一下,一个系统如何能在短时间内理解并再现复杂的音频特征,这无疑是人工智能领域的一项重大突破。
在技术实现上,OpenVoice运用了先进的模型,比如卷积神经网络(CNN)和循环神经网络(RNN),这些技术能够帮助系统从大量数据中学习,并不断优化克隆效果。难道这不令人惊叹吗?我们已经进入了一个可以通过声音来传达情感和故事的新时代。
三、OpenVoice的优势
1. 准确的音色克隆
OpenVoice的第一个优势就是其高准确度。通过对参考音色的精细分析,它能够生成多种语言和口音的语音。举个例子,如果你只是提供了一段英语的音频,OpenVoice可以在此基础上,生成法语、德语甚至是西班牙语的版本。这对于多语言环境的公司、教育机构,甚至内容创作者来说,真的是一个福音。

你是否想过,这种技术可以如何改变我们的交流方式?想象一下,国际会议上,各国代表能够用自己的母语进行发言,同时听到翻译的声音与自己的声音相似,这样的体验是否会让沟通变得更加顺畅?
2. 灵活的音色控制
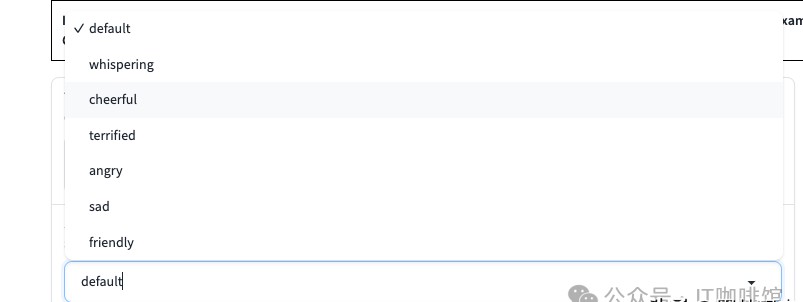
第二个优势则是其灵活性。用户可以根据需要调节语音的风格,包括情感(快乐、悲伤、愤怒等)、口音、节奏和语调等。这种灵活的定制化选项,赋予了用户极大的创作自由。你是否曾想过,如何让一个机器人听起来更像一个真实的人?OpenVoice的多样性正是为此而生。
在制作有声书时,作者可以选择不同的情感表达,以此来增强故事的沉浸感。这种技术的应用,是否会使文学作品的传播方式发生巨大的转变?
3. 零样本跨语言语音克隆
OpenVoice的“零样本跨语言语音克隆”功能可能是最具颠覆性的。在传统的语音克隆中,生成的语言和参考语言通常需要在大规模的多语言训练数据集中出现。但OpenVoice打破了这一限制,用户只需提供任意语言样本,即可生成所需的声音。这一功能的实现,有助于加速全球化进程,想象一下,来自不同文化背景的人们能够轻松地进行交流,这将对社会的多元化产生怎样的影响?
四、使用OpenVoice的途径

1. 在线渠道
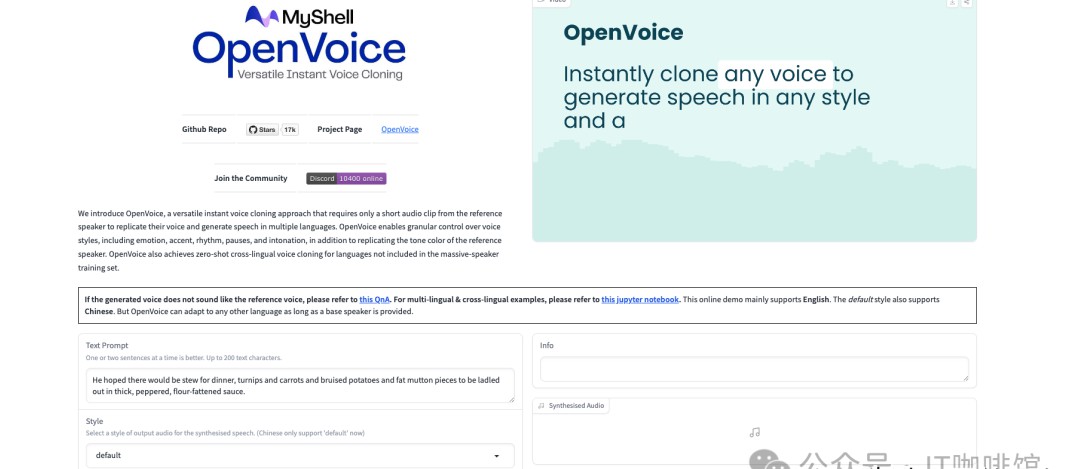
对于大部分用户来说,使用OpenVoice的最简单方式是通过几个主要的在线渠道。比如,LeptonAI、MyShell和HuggingFace,这些平台提供了便捷的方式让用户体验声音克隆的魅力。
在MyShell上,用户可以直接使用免费的TTS(文本转语音)和即时语音克隆服务。是否曾想过,利用这些工具,普通用户也能轻松制作出高质量的语音内容?这对于内容创作者、教育工作者等,都是一个巨大的助力。
2. 本地部署
如果你对技术有一定了解,想要更加深入地体验OpenVoice,可以选择本地部署。你需要基本的Linux、Python和PyTorch知识,以及一些服务器资源。安装过程并不复杂,但可能需要一定的技术背景。
当你成功在自己的设备上部署OpenVoice后,那种成就感和对声音克隆技术的掌控感,是否会让你对这一领域产生更深的兴趣?在这个过程中,你将不仅仅是一个使用者,更是技术的探索者。
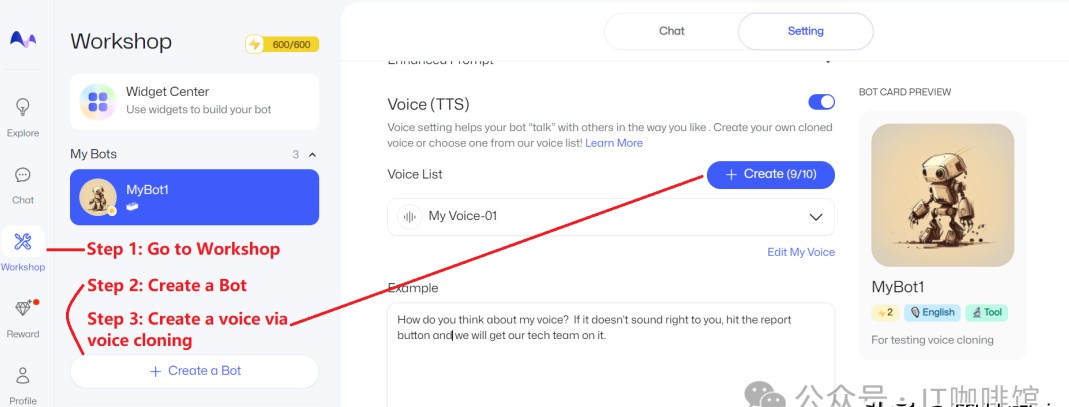
3. 使用MyShell的体验
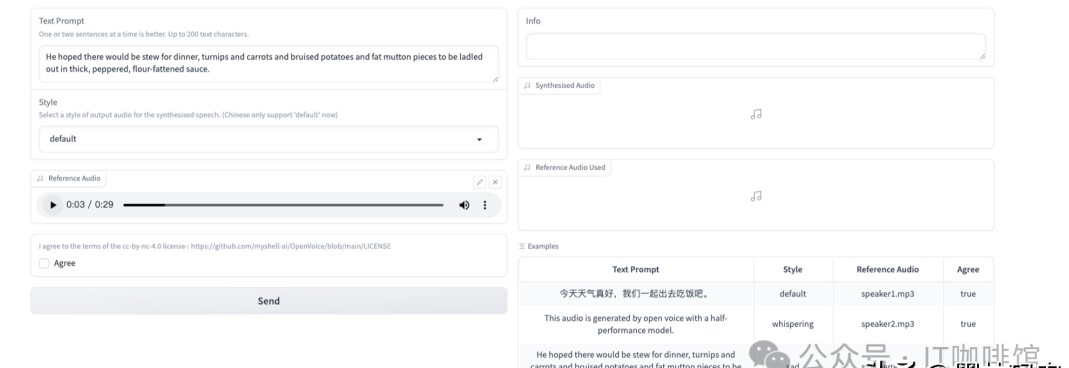
在MyShell中,用户可以创建自己的机器人,并借此使用OpenVoice的所有功能。这个过程中,用户可以体验到不同AI工具的结合,比如文生图、语音、视频等,所有这些都在同一个平台上实现,这种便利性是否会激发你的创作灵感?
想象一下,你可以用OpenVoice为自己的短视频配音,同时使用文生图工具生成相关的视觉内容,这样的多媒体创作体验,是否会让你感到无比兴奋?
五、操作指南
1. 生成音频的步骤
使用OpenVoice生成音频其实很简单。首先,你需要在平台上输入需要转化为音频的文字,然后根据需要选择合适的语气,接着上传参考音频。最后,点击“开始转换”,等待新音频的生成。
你是否会好奇,生成后的音频质量如何?很多用户在体验中表示,生成的音频不仅自然流畅,而且语气和情感表达都很到位。这样的效果是否会让你对声音克隆技术刮目相看?
2. 多语言支持
在使用OpenVoice时,用户可能会注意到在线环境对英文的支持更为完善,而中文支持稍显不足。不过,OpenVoice本身其实是支持多语言的,只需要安装相应的模型即可。这一过程并不复杂,但对于不熟悉技术的用户来说,是否会感到有些挑战?
当这种技术能够支持更多语言时,将对跨国企业、国际会议以及多元文化交流产生怎样的影响?是否会让我们更容易理解和接纳不同的文化?
六、技术展望与局限
1. 技术目标与愿景
OpenVoice的目标并不仅仅是提供一个好用的工具,而是希望通过不断的努力,让开源声音克隆技术能在质量上与商业产品相媲美。这样的愿景是否让你对未来的声音技术充满期待?
我们或许会看到更多基于OpenVoice的创新应用,比如个性化语音助手、虚拟现实中的角色配音等。想象一下,当你的虚拟助手能够用你最喜欢的明星的声音与您对话时,会是怎样的体验?
2. 使用中的注意事项
OpenVoice并不是完美的产品。尽管它在大多数场景下表现良好,但在某些特定情况下,克隆效果可能不尽如人意。这也提醒我们,任何技术的使用都需要理性。你是否认为,技术的完善与用户的反馈之间存在着一种密切的关系?
这项技术的主要目标用户是研究人员和开发人员,而非普通消费者。对于后者来说,是否有必要对这种技术的使用有更多的了解和尝试?这或许是一个值得思考的问题。
七、结论
OpenVoice无疑是一项令人兴奋的技术,它不仅为声音克隆带来了新的可能性,更为我们的沟通和表达方式打开了新的大门。随着技术的不断进步,未来我们将看到更多基于声音的创新应用。
技术的应用与发展永远是一个开放的话题,尤其是在伦理和隐私等方面,我们有必要保持警惕。对于声音克隆技术的探索,也许才刚刚开始。你准备好迎接这个声音的新时代了吗?