
ICLR 2024:阿里NUS新框架,大模型事实性飙升!
ICLR 2024 | 阿里、NUS团队揭秘:全新知识链框架如何提升大语言模型的事实正确性
在自然语言处理(NLP)的广阔天地里,大语言模型(LLMs)无疑是一颗璀璨的明星。它们以超凡的语言理解和生成能力,引领着对话、翻译、代码生成等领域的革新。随着这些模型在各个领域的广泛应用,一个不容忽视的问题也逐渐浮出水面——那就是LLMs生成内容中的事实性错误。为了解决这一难题,阿里与新加坡国立大学(NUS)的研究团队联手,提出了一种全新的知识链(Chain-of-Knowledge, CoK)框架,旨在通过动态整合异构知识源,有效提升LLMs的事实正确性。
大语言模型在为我们带来便利的也因其概率生成的本质,难以避免地在内容生成过程中出现事实性错误。想象一下,当你正在与一个基于LLMs的智能助手聊天时,它突然给出了一个完全错误的历史事实,这不仅会影响你的使用体验,更可能误导你的判断。因此,如何增强LLMs生成内容的正确性,成为了NLP领域亟待解决的问题。

现有的解决方案中,检索增强生成(RAG)方法通过将LLMs与检索系统结合,利用外部事实知识指导生成过程。这些方法在实践中暴露出了一些局限性。例如,它们通常使用固定的知识源,无法针对特定领域检索到专门的知识;在生成检索查询时,主要依赖于LLMs本身,而LLMs在自然语言句子上的预训练使其在生成结构化查询时表现不佳;此外,现有的RAG方法还缺乏逐步纠正能力,可能导致错误的累积和传播。
针对以上问题,阿里与NUS团队提出了知识链(CoK)框架。这一框架通过从异构知识源动态整合信息,为LLMs提供了更广泛、更可靠的事实依据。具体来说,CoK框架包括三个阶段:推理准备、动态知识适配和答案整合。
在推理准备阶段,CoK框架首先会对输入的问题进行初步解析,识别出相关的知识领域,并准备一些初步的推理和答案。如果初步答案之间存在分歧,CoK会进入下一个阶段——动态知识适配。

在动态知识适配阶段,CoK利用一个自适应查询生成器(AQG),根据问题的特性和领域知识,生成不同类型的查询语言(如SPARQL、SQL、自然语言句子等)。这些查询会被发送到多个异构知识源(如Wikidata、表格等)进行检索,获取与问题相关的结构化和非结构化知识。然后,CoK会利用这些检索到的知识,对初步推理进行逐步纠正,确保每个推理步骤都基于可靠的事实依据。
在答案整合阶段,CoK会将纠正后的推理步骤整合起来,形成最终的答案。与以往的RAG方法相比,CoK的逐步纠正策略有效减少了错误传播的可能性,提高了推理的准确性。
知识链(CoK)框架的核心在于其自适应查询生成器(AQG)和逐步纠正策略。AQG能够根据问题的特性和领域知识,生成多样化的查询语言,从而充分利用异构知识源中的结构化和非结构化知识。这种跨领域、跨语言的能力,使得CoK能够更全面地覆盖各种知识领域,提供更准确、更全面的答案。
CoK的逐步纠正策略也是其独特之处。通过逐步纠正推理步骤,CoK能够在每个步骤中都确保基于可靠的事实依据,从而有效减少了错误传播的可能性。这种策略使得CoK在处理复杂问题时表现出色,能够给出更准确、更可靠的答案。
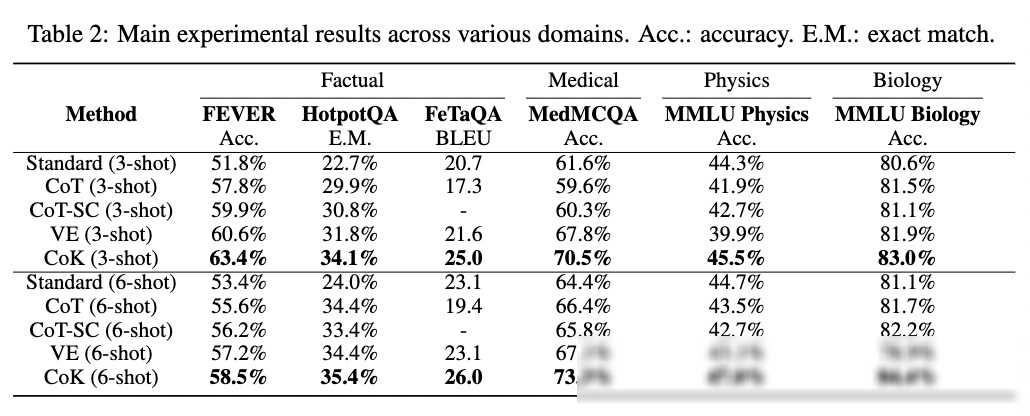
为了验证知识链(CoK)框架的有效性,研究团队在多个领域进行了广泛的实验。实验结果表明,与现有的RAG方法相比,CoK在常识、医学、物理和生物等多个领域都取得了显著的性能提升。具体来说,CoK在常识问答数据集上的准确率提高了4.3%,在医学、物理和生物领域的知识型任务上也表现出色。
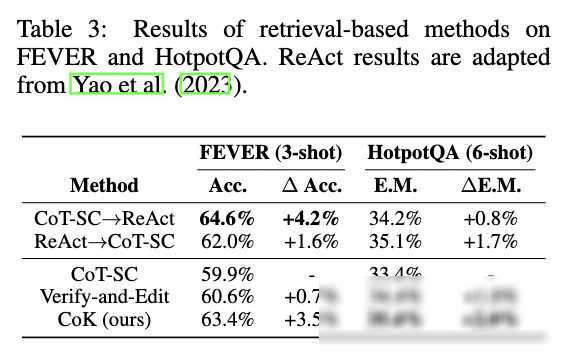
此外,研究团队还与其他最先进的方法进行了对比。结果显示,CoK在多个数据集上都取得了更好的性能表现。特别是在HotpotQA数据集上,CoK相比ReAct方法提高了2.0%的准确率,而ReAct只有0.8%的提升。这一结果充分证明了CoK框架在处理复杂问题时的优势。
知识链(CoK)框架的提出,为提升大语言模型的事实正确性提供了新的思路和方法。随着技术的不断进步和应用场景的不断拓展,我们有理由相信,CoK框架将在未来发挥更大的作用。
随着更多异构知识源的加入和整合,CoK框架将能够覆盖更广泛的知识领域和应用场景。这将使得LLMs在更多领域都能够提供更准确、更可靠的答案和服务。
随着技术的不断进步和优化,CoK框架的性能也将得到进一步提升。例如,通过引入更
